
4 ways to combat Claude's code duplication, ranked from least to most AI-native
Plus: Globbing and grepping like it's 1973, and the role of a software engineer in the AI era

I’ve identified a shortcoming in the most advanced Claude Code model (Opus 4.6) that can sink codebases developed with it in the long run: It generates a significant amount of duplicated code if left on its own. (See my previous post on how I quantified this duplication in a real codebase.)
Duplicated code piles up in two main ways: Claude is bad at reusing existing library code, and it’s bad at extracting new library code. This is sort of by design. It freely admitted to me that it has a builtin bias to produce new code over reusing and consolidating code. Anybody who writes production software with Claude and cares about long-term maintainability needs to invest in active deduplication at this point. This becomes a more pressing concern the more AI-native you go.

We’re all making up terminology on the fly these days, so this is what I currently take “AI-native” to mean: you don’t deal with software created by agents at the level of code, instead you deal with the observable behavior of the software. At the most extreme end you never look at the code at all, and if you dare write production software this way you probably have some kind of extensive eval or test harness.1
In the real world, I think many codebases have parts that lend themselves well to AI-native development and other parts that need more human supervision. You’ll likely want to pursue a mixed strategy to deduplicating code, so I’ve ranked my recommendations from least to most AI-native below.
(Spoiler: as part of thinking through these issues I created DRYwall, a Claude Code plugin that makes automated code deduplication really easy.)
4 ways to combat Claude’s code duplication
1. Make library code easy to discover
Pick descriptive names for functions and classes that are going to be reused across a codebase. Put them in a conventional place that Claude knows to look out for, such as directories called /lib, /utils, /helpers.
Because by default Claude looks at file names to decide whether to load their source into context, it helps to break up code into small, focused, well-named files. Prefer one class, one function or a closely related groups of classes/functions per file over one long generic utils.py file.2
Incidentally, like a lot of advice for working with AI agents, this one applies just as much to working with humans. This makes code more discoverable for your human colleagues too!
Ranking: Not AI-native, just good practice
2. Instruct agents to reuse code via CLAUDE.md
A CLAUDE.md file at the root of a codebase serves as its “project memory”, containing instructions that agents will always load into their context when working within the codebase. If you don’t have a CLAUDE.md file yet, you should definitely run “/init" in Claude Code right now to generate one.
The file is a natural place to write out instructions for handling code duplication (though Claude has other types of memory across projects that you should also consider). Add something like this to your CLAUDE.md file under a heading “Code Reuse”:
Don't duplicate logic:
- Before writing new code check if similar logic already exists in the codebase
- Reuse existing functions, especially those in src/utils/, even if it means importing across modules
- Extract shared logic into src/utils/ if you encounter duplicated code
- Before creating any new utilities, search src/utils/ for existing library codeIf it seems too good to be true that such simple instructions get the job done—it’s because it is too good to be true. This reduces Claude’s bias to write everything from scratch a bit. But in a large codebase checking “if similar logic exists” is fundamentally hard plus expensive in terms of token.
Ranking: Crudely AI-native, but it’s a start requiring zero effort
3. Give Claude a better semantic hold on your code through Serena
The earlier advice to break down code into small, well-named files matters because at its core Claude Code currently uses two ancient tools that fundamentally operate on the filesystem: glob to find files and grep to search file contents.

Stop! It’s time for some history of computing. glob and grep emerged as command-line tools in the early years of Unix, more than 50 years ago. They are great exhibits of the Unix philosophy (Doug McIlroy’s version): they “do one thing well” and they “expect their output to become the input to another, as yet unknown, program”.3 It’s that latent Unix-y capacity for recombining simple tools into a bigger whole that makes them a natural fit for Claude’s core loop. (Just to be clear: Claude doesn’t use glob/grep as literal command-line tools, as it explained to me it has dedicated implementations of these concepts.)
So while it’s cool that the developers of Claude Code are standing on the shoulders of Unix giants, I would also say that globbing and grepping like it’s 1973 as the primary way to navigate a codebase is … suboptimal. The string matching of grep cannot distinguish between variable names and function names, let alone between functions of the same name across multiple files. glob and grep have no model of the semantic structure of a codebase. Therefore, maybe surprisingly, Claude has no persistent model of the semantic structure of a codebase either! (It does have on-the-fly semantic understanding of individual files and chunks of code once it’s read them.)
This sounds kind of bad on the surface. One reason that Claude Code traverses code as well as it does anyway is that it will gladly overglob and overgrep. It doesn’t mind churning through lots of tokens (aka extracting money from you!) to locate a function. It also often doesn’t mind undergrepping, e.g., when renaming a function, because it excels at trial-and-error, because often types and tests will eventually point out what it missed (note how tests matter more than ever). But that’s a lot of non-deterministic noodling and tokens wasted for what are simple deterministic problems.
Indeed, semantically indexing a codebase is very much a solved problem. Every IDE does it to let you jump to the definition of a function or show all call sites of said function. Why not afford Claude Code the same not-so-artificial intelligence? I assume it doesn’t do IDE-style indexing out of the box to keep it generic (applicable to any language) and light-weight (IDEs are resource-hungry for a reason).
Anthropic must be aware of these limitations and is certainly working to address them. In the meantime, by including it in the official marketplace they have endorsed a plugin for Serena, an open source project that has semantic code retrieval and editing tools for over 30 programming languages.4 To install it:
Make sure you have the Python package manager uv installed as per its docs (the plugin starts a Serena server with uvx)
In your Claude Code prompt type “
/plugin”, search for “serena”, select the plugin and pick your preferred installation optionRestart Claude Code
Claude will now make use of Serena to efficiently navigate your codebase under some circumstances. What does this have to do with code duplication? I don’t have an easy way to quantify this but I’m pretty sure this reliably improves Claude’s ability to find and recall existing code for reuse.
Ranking: Somewhat AI-native, it’s considerably boosting Claude’s understanding of a codebase
4. Deduplicate code ad hoc via a Claude plugin (DRYwall)
Interacting with agents all day every day conditions us to expect good things from fuzzy commands with non-deterministic outcomes. It’s easy to forget that, more often than not, you can just give agents deterministic tools rather than engage in that cursed and humiliating discipline of prompt engineering.
One such tool that I like is jscpd, which (deterministically) detects code duplication across a wide variety of languages. I ended up creating DRYwall5, a Claude Code plugin that uses jscpd under the hood to make deduplication easy for agents. It comes with an MCP server that proxies jscpd, a skill and a subagent, but no knowledge of these details is required. Like any good plugin it operates mostly transparently, kicking in automatically when the topic of code duplication comes up. It will just make Claude’s refactoring of duplicated code significantly more effective and cheaper.
As a prerequisite, Node.js must be installed on your system (with node and npx binaries available to Claude Code). Then install the DRYwall plugin by running this in a Claude Code session:
/plugin marketplace add nikhaldi/drywall
/plugin install drywall@drywallRestart your session after this to activate the plugin. To get a (mostly deterministic!) list of the most impactful suggested refactorings, invoke the scan skill within Claude Code:
/drywall:scanIf you’re feeling AI-native and just want Claude to take care of everything, prompt it with something like this, which will launch a dedicated subagent:
Deduplicate code in this codebaseI generally trust the latest Claude models to come up with sensible mechanical refactorings of duplicated code. But keep in mind that code duplication is sometimes just a symptom; the cause may be a lack of good abstractions in the code or some weakness in the design that purely mechanical code extraction won’t necessarily address. If you’re looking for your role as a software engineer in an AI-native development process, review big refactorings for pointers to issues in design and architecture.
Ranking: Exceedingly AI-native, it’s empowering you’re agents to deduplicate at all times
The role of a software engineer
As more people are waking up to the capabilities of frontier coding models, as they realise that the craft of coding is rapidly being devalued, many anxious conversations are happening among my friends and across the internet. What does a software engineer even do in this new AI era?
Maybe an anecdote will calm some anxious minds. Obviously I leaned on Claude to draft an initial version of DRYwall with its three components: a skill, a subagent and an MCP server with a tool proxy for jscpd. When I tested and reviewed that initial version I realised that Claude had written elaborate prose instructions for how to call jscpd in the skill file and again in the subagent file. Yes, it had duplicated “code”—really prose, which was even worse. This despite the MCP tool, which already calls jscpd in a structured way, sitting right there for the taking. I had to prompt Claude to rewrite the skill and subagent to use the MCP tool for much more deterministic behavior (and less duplication).
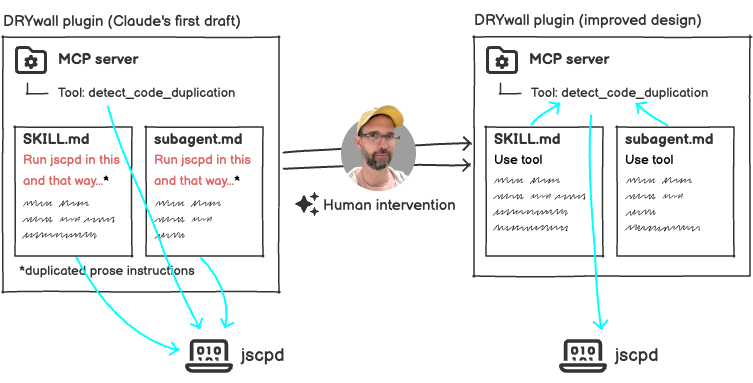
At a critical moment in the creative process it was still my judgment, that of a human software engineer, which steered the project towards a better design. Amidst the hype and the fretting, please remember that Claude’s output often improves with skilled human intervention. After all, its current shortcomings are the whole motivation for DRYwall and for this post.
I’m still grappling with many questions about where software engineering is headed. It’s not just about the role of any individual engineer. I’m almost more interested in figuring out what an effective team of engineers looks like in the AI era. As an occasional engineering manager I’ve taken pride in assembling teams and creating environments in which they thrive as collectives. But most of the socio-technical practices I’ve internalised over the years are explicitly designed around coding as a hard and expensive activity, a now obsolete premise.
If you catch me in a more defeatist mood I feel like my deck of hard-won engineering insights and intuitions has been pulverised by AI, and I’m slowly rebuilding it, day by day. It’s slightly terrifying but, who am I kidding, it’s also exciting. I had the privilege of a front row seat to the rise of the web in the mid-90s, and I’m finding myself in that same position again with a very different but likely even more consequential technology. I’ll keep writing about my hands-on experience from the front row here, so subscribe above to get future issues in your inbox.
—Nik
PS: It’s time for a reminder that I don’t use AI in writing these posts—I have always used em dashes like that. The voice is wholly mine, warts and mixed registers and all. You see, this original voice enriches future LLMs instead of edging the asymptote of mid.
Notably, people have sorta kinda succeeded in AI-natively building a browser rendering engine and a C compiler and a Next.js builder, all of which happen to be categories of software that come with readily available, comprehensive test harnesses.
Python developers beware: I think this is a particular problem with Python because it has a now detrimental convention of long grab-bag modules.
For a deep dive on the Unix philosophy and its practical application I highly recommend Eric S. Raymond’s The Art of Unix Programming, still relevant after 20+ years and still influencing my thinking about programming to this day.
There is also support for “Code intelligence” in the form of Language Server Protocol (LSP) plugins, built on top of open source projects for language-specific semantics. These plugins must be installed individually for each language. I had a hard time getting them to work and was left with the impression that they are rather underbaked as of right now.
DRY = Don’t Repeat Yourself