
Reading in a Foreign Language
Natural Language Processing (NLP) in aid of language study. The VSCode/Copilot experience out of the box. What's still hard despite AI.

Welcome to the inaugural issue of this newsletter! Every two weeks I prototype some new piece of software, navigate the rapidly evolving landscape of AI coding tools and live to write about it.
In this issue: Lexiglo, an app to help you read text in a foreign language, as you’re trying to level up in the language. The impatient can just check it out — but read on for commentary.
Leveling up through literature
Earlier this year I had a breakthrough in my self-guided study of the Greek language.
I had been studying “easy Greek readers” for a while, stories written in a limited vocabulary tailored to language students. Then one day on a whim I picked up a serious novel in Greek, actually a translation into Greek of The Vegetarian by Han Kang, the 2024 Nobel prize winner from South Korea. I discovered that even though I knew as few as 50% of the words in a sentence I was able to follow along just fine, if I looked up some of the words that seemed crucial to understanding the gist of the sentence.
I started reading the book with my phone sitting next to it, translating unknown words with DeepL (which is slightly better at Greek than Google Translate) and capturing useful ones in the flashcard app Anki for later spaced repetition.
I soon threw those dumb “easy readers” in the bin. Even if it was slow going, sometimes just a few sentences a day, literature with depth and adult themes was so much more engaging! It took me several months to get through the whole novel but my vocabulary, reading speed and grasp of the grammar improved dramatically in the process.
This got me thinking about what an ideal foreign language reading experience should be like, and I implemented some of my ideas as Lexiglo during the last two weeks.
(For the quickest demo choose a language and then click on “Load sample text” in the bottom left.)

The app highlights words based on their frequency — their likelihood to appear in a conversation — and based on your proficiency.
Words in green are those you may want to look up and train given your proficiency level
Words in yellow are significantly beyond your proficiency level or just rare, so you probably shouldn’t bother with them
This is a standalone web app because that was the easiest way for me to play around with and demonstrate these ideas. I don’t actually think it has that much value as a standalone user experience. Consider this my suggestion for what should be integrated into existing e-readers like the Kindle.
Some basics of Natural Language Processing
At the core of its backend, Lexiglo assigns each word in a text a metric for how frequently it occurs in a language. I assembled a few standard techniques from the field of Natural Language Processing (NLP) to achieve this.
Tokenisation identifies individual words in a text. This may sound trivial but it needs attention because of grammatical quirks in different languages. In English, the contraction “we’re” should be recognised as two words, and the “re” should be treated as equivalent to “are” (if we’re going to assign it a word frequency). I rolled my own tokenisation with some language-specific rules.
Stemming reduces a word to a root, in our case with the goal to treat declinations and variants of a word as equivalent. In English, the noun “boat” and its plural “boats” are clearly the same word for our purposes (they should both reduce to the stem “boat”). But is “boating” a separate word? Context often matters and even then grey areas always exist that stemmers choose to resolve in different ways. I mostly use the stemming from hunspell.
Word frequency data is compiled by counting words in a large body of text. I chose this free resource derived from TV/movie subtitles. Given the nature of subtitles the data skew towards conversational language which is a great fit for language learning. The secret sauce of Lexiglo (if there is such a thing) is how this raw data is turned into a database for efficient look up.
Just because these techniques are well understood doesn’t mean it’s easy to deploy them in a real-world application. I’m not an NLP expert by any stretch and had limited time, so I simplified and cut corners.
Shout out to one particularly intractable problem that I ended up just not addressing: Named Entity Recognition (NER), or distinguishing proper names from other words. I would like to ignore the names of people, towns, brands, etc. in annotated texts — but I couldn’t see a way to do it reasonably quickly.
In general though, the approach extends easily to all of the top 20-ish languages in the world, even though each new one requires some customisation. The supported languages in Lexiglo now (English, French, German, Italian, Greek) are those in which I’m fluent enough to judge the quality of the output. And quality definitely varies. I’m 90% happy with English and German, where I invested the most time. I’m less happy with Greek because its hunspell stemming was useless and I had to resort to a simplistic stemmer (Snowball). The quality of French and Italian is a bit of an unknown, since I added that in very quickly at the end, with the deadline for this post fast approaching.
Fine, I’ll come clean. It wasn’t me — It was an AI agent that added in French and Italian. There is no AI per se in the backend but I did use AI coding assistance throughout. At this stage there was enough precedent in the codebase for an agent to implement sensible language-specific rules by itself.
How I used AI: VSCode/Copilot out of the box
For this project I somewhat artificially restricted myself to VSCode and its integrated AI features. I knew from the outset I would write all code in TypeScript, for which VSCode is the editor of choice. My sense is also that many developers just learning to code default to it, and I wanted to understand what that experience would be like.
The experience is certainly fundamentally different from what it was just 3 years ago, when the first AI code models were just releasing. At some point during the last year VSCode rebranded as “The open source AI code editor”, a claim I will grant them. Out of the box it emphasises two core AI features:
Next edit suggestions: It predicts likely next edits you’d make in the scope of a single file and lets you accept suggestions with the tab key. Under the right conditions you type out a function header and then just hit tab a few times for the implementation of the function to autocomplete.
Agent mode: A chat-based interface to an agent that can suggest larger edits across multiple files, sitting in the right-hand sidebar by default.
Both of these features are tightly integrated and intuitive, with essentially no learning curve. By default they are enabled and backed by the free tier of GitHub Copilot, if you’re already logged into your Github account. By the time I hit the usage limit of the free tier I was relying on it so much that I gladly upgraded to Copilot Pro for the price of two mid-market matcha lattes ($10/month).

I would say the “next edit suggestions” increases my net coding speed by some consistent factor, maybe by about 20%. The impact of agent mode is harder to pin down, it can vary a lot case by case. When I prompt an agent for a big change I then still have to comb through the code to ensure it’s really doing what I wanted. Paradoxically, writing code can be faster than reading it.
The Copilot experience shifted my frame of mind while coding in a way that took me by surprise: When a task would have previously required intense focus, would have required me to be in a flow state, I was now able to coast sometimes, only partially paying attention. I was sometimes able to just vibe, as it were.
Agents can be slow (for now); while I’m waiting around for their response I’m forcibly switching context, checking my phone, sipping on the matcha latte, watching that YouTube short, or, in any case, ejecting out of flow state. I have complicated feelings about this shift towards a more distracted or distractible coding. It certainly will make coding more accessible to more people. On the other hand, skills I’ve spent a whole career cultivating — a long attention span, building up execution context in my head, entering and maintaining flow — may lose status.
I have some predictions about what skills may rise in status instead:
Reading code: Understanding code at a glance has always been remarkably hard but remarkably useful, given the truism that code is written once but read many times over. In a world where you spend most of your day reviewing your agent’s code it becomes a critical skill.
Decomposition: I’ve gotten the most out of AI models when I prompted them at the right level of abstraction. A good function name at the right level of granularity lends itself to autocompletion. The right size of task given to an agent is more likely to produce usable code.
Interestingly, senior developers would already have been exercising these skills regularly. In most professional settings developers review each other’s code on a daily basis, and they would have acquired a good sense for decomposition from having to write a lot of code by themselves (without AI assistance). I think there’s a possibility that, once the dust settles a bit, benefits from AI accrue to experienced developers moreso than to junior ones.
How do we effectively teach these skills to junior developers just starting out whose default environment is now AI-enabled? I’m not sure because I don’t think they were formally taught to me either.1
What’s still hard
I suspect this will be a recurring section in this newsletter. What remains tedious, time consuming or just plain hard, even with current AI fidelity? Or in other words, where are potential opportunities and market gaps?
Wobbly stack
I wanted to work in an end-to-end TypeScript stack for this because I had never done it before and because I was hoping a consistent language across client and server would let me move the fastest. I settled on Blitz.js as a framework since it promised opinionated defaults for exactly this kind of stack.
Blitz.js builds on Next.js which performs … some kind of magic to bring client and server closer together (do not ask me to explain). Blitz has an RPC layer that further blurs the boundaries between client and server, which in principle I like a lot. Blitz also sets you up with Vite for testing by default.
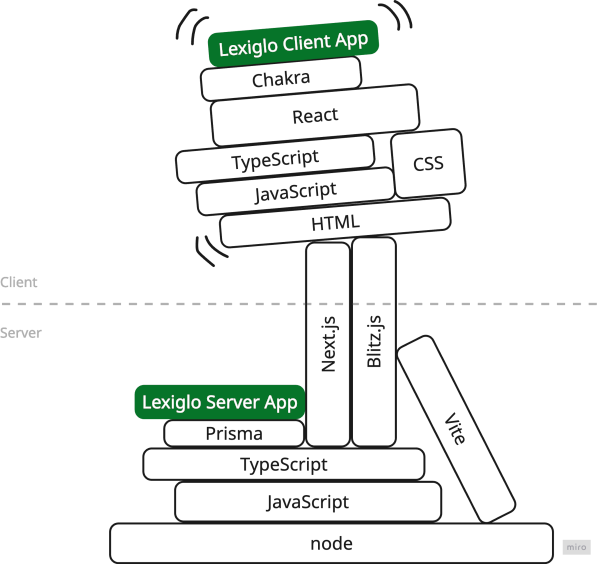
I believe this is what they call a simple stack. I added the Chakra UI component library myself, everything else comes out of the box with Blitz. To be fair, on paper all of these choices are entirely sensible. In practice, many parts of the stack will have leaky abstractions to some degree, exposing some of the underlying complexity.
At several points I lost a significant amount of time tracking down obscure compatibility issues between Next, Vite and TypeScript. These were obscure issues as in: neither AI nor Google offered me an obvious solution. In one particularly bad case I had to write a custom Vite plugin, just so I could import nodehun, the native hunspell bindings as packaged for node (now memorialised in a gist because I’m surely not the last person with this problem).
A bigger, more durable codebase would simply accumulate solutions for these issues over time and ammortise the cost, but for the purpose of rapid prototyping the hidden complexity of this stack may be a liability.
I don’t have a clear conclusion here. Again, on paper I can’t fault this set up and in principle I like Blitz. Maybe the insight is just that architecture as such remains hard. And if you really look at them closely, the standard architectures of modern web apps are inherently a bit weird and wobbly.
Responsive design
User-friendly design for small phone screens has always been hard — and I don’t think that’s just because I’m not actually a designer (I only play one on TV in this newsletter). Making a design responsive, meaning that it works well both on large and small screens, is extra hard.
In many situations you’re simply forced to reckon with responsiveness as a web developer. If a design isn’t responsive you’re liable to lose either most mobile users or most desktop users. I estimate that 60% of people who click through to the app from this post will be on phones. So I put in the work to retrofit my initial wide-screen design for phones.

This was way too fiddly. I’m still not satisfied with the resulting usability on phones, mainly because the keyboard gets in the way of the core interactions sometimes.
Copilot just wasn’t helping much with this. I partly blame the unusual interaction patterns in the app, for which it likely can’t draw on much prior art. But it also felt as if the code models don’t have a concept of what generated code visually looks like or whether some specific layout of elements would make sense to a user.
It’s not that the code-level frameworks for responsive design are lacking. I used Chakra here and it did everything I needed it to do. But there’s a market for dedicated AI tooling to aid responsive design. I’ll need to try out some of the “AI design” products out there to find out how well they address this already.
Before opening up VSCode again a couple of weeks ago I hadn’t written any serious code for almost 2 years. As a CTO in a fast-growing startup I’d been too absorbed by management and too far removed from ground-level engineering. So I’m coming at the hands-on realities of recent advances in AI with fresh eyes. It’s been illuminating and fun to get back in the game. Subscribe above and come along for the ride.
—Nik
BTW, I do not use AI assistance in writing this newsletter — I’m worried it would flatten my voice and dull my thinking with too many mid ideas.
Did you get a chance to try Cursor? I use Copilot only rarely, when using Github codespaces, so hard to get a feel for it.
But I'm impressed with the latest default model from Cursor. Comprehensive like the other "thinking" models, but can also do simpler targeted / repetitive tasks like the simpler models.
Seems it can go 10 or more cycles (e.g. 1. implement, 2. fix that, 3. address next point in todo, 4. fix that, etc...). And mostly correct (it keeps the previous constraints in place). For tests the maximum I tried so far was to let it fix ~50 tests, one by one. It was done in ~7 minutes, but correct.
For context, this was a project with ~10K lines of code, and relevant code being spread only across ~6 files. Greenfield Rust project, see https://github.com/django-components/djc-core/pull/17.