
Growing Code in the Lab
A full-stack appreciation of autoresearch architecture

What is intelligence, really? Isn’t it just falling down, then learning to get back up, then falling down again, and then eventually learning to stay upright and to put one foot after the other, locomoting to the other side of the room into a parent’s open arms?
One reason AI coding agents seem to be possessed by intelligence is that they are built for trial and error, getting up and falling down tirelessly until they stand up a successful solution, usually meaning one that compiles or passes some kind of test.
A few weeks ago Andrej Karpathy took the inherent trial-and-error design of coding agents one step further. He set up an autonomous research loop for an agent to make iterative progress towards a measurable goal—and he called it autoresearch. He published his code on Github, which is actually a solution to the pretty narrow problem of training LLMs, not something that most people ever have a use for. It made a huge splash anyway because it carries a whiff of the early-stage singularity (is an LLM improving itself autonomously here?) but also because it was apparent to many that it exemplifies a new architectural pattern with wide application. To quote Karpathy himself from a tweet:
All LLM frontier labs will do this. […] You spin up a swarm of agents, you have them collaborate to tune smaller models, you promote the most promising ideas to increasingly larger scales, and humans (optionally) contribute on the edges.
And more generally, *any* metric you care about that is reasonably efficient to evaluate […] can be autoresearched by an agent swarm. It’s worth thinking about whether your problem falls into this bucket too.
The autoresearch pattern is one answer to a question I’ve personally been grappling with: how do you set boundaries for long-running, unsupervised agents in order to have some confidence that they don’t produce complete garbage?1
In my head I currently break down the pattern into these components:
The artifact under research—often a piece of code, but it could be data, a set of hyperparameters or anything else lending itself to iterative optimisation
A metric to optimise for and a method to compute that metric for the artifact
Research instructions for the agent that explain the metric and anything else the agent needs to run a single experiment on the artifact inside the research loop
A record of kept and discarded experiments for the agent to refer back to when planning new experiments—this includes metrics for each experiment and ideally also a snapshot of the artifact (e.g., in the form of git commits if it’s code)
A research loop orchestrator which computes metrics, maintains the record of experiments and generally supervises the agent (e.g., it may stop the agent to prevent runaway costs)
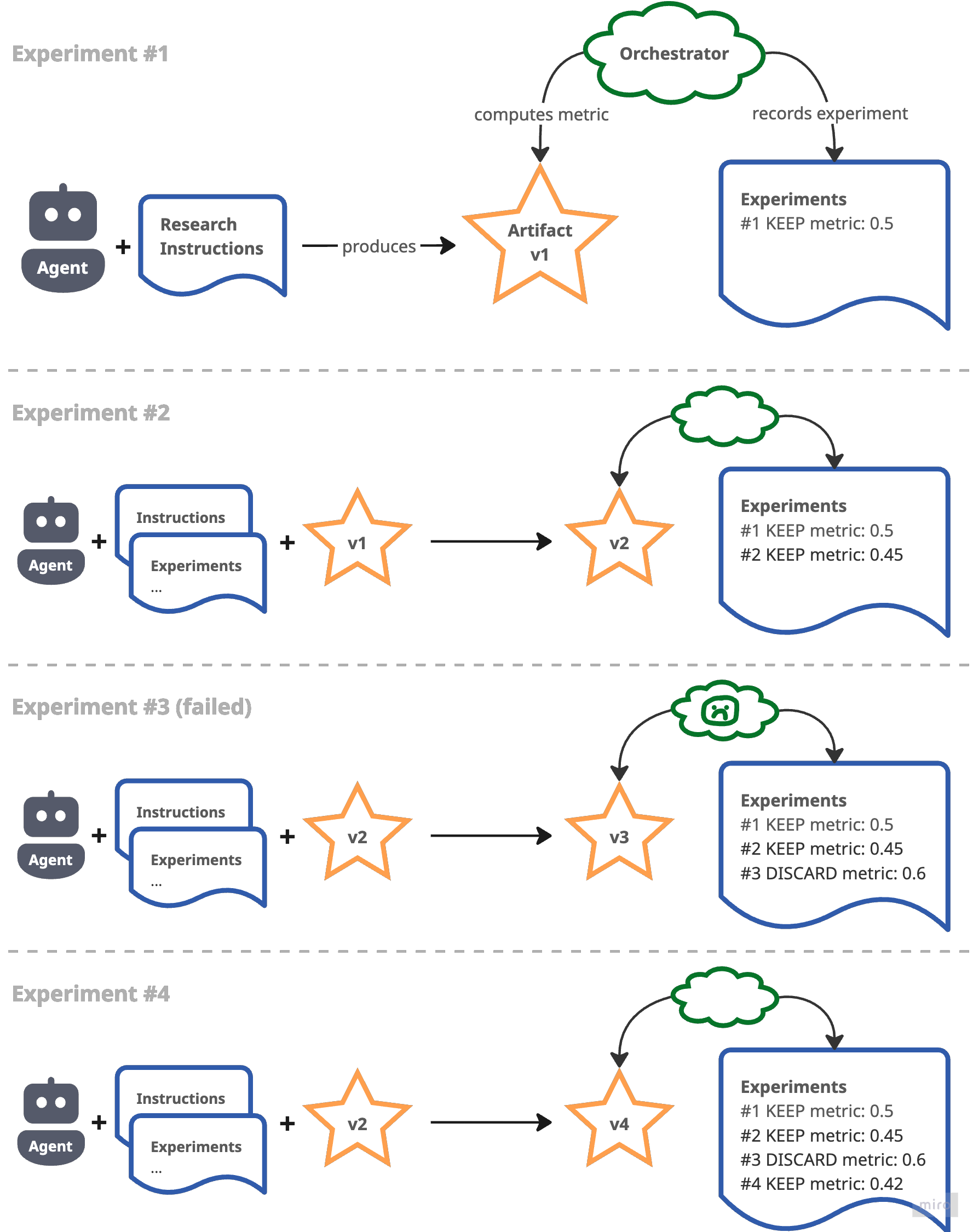
For each experiment in the research loop the agent takes the research instructions, the prior list of experiments and the artifact from the last successful experiment as its “prompt” and produces a new version of the artifact. The orchestrator computes the metric for the new version of the artifact and records the experiment as successful if the metric improved, failed otherwise. In a simple setup (like Karpathy’s version) the agent acts as its own orchestrator—in my experience this is risky because the agent may hallucinate fake metrics or go off the rails in other unpredictable ways.
The lab approach to autoresearch
After Karpathy’s initial viral tweets sent my head spinning I quickly identified a problem I was facing (more on that further below) that I could jam into an autoresearch-shaped bucket. Once I had succeeded at that I simply had to extract my own little framework, which I released as Autoresearch Lab.
The design of Autoresearch Lab was motivated by my circumstances, extrapolating a bit to make it as widely applicable as possible:
I wanted to run research loops to produce both native Android and native iOS code, so it needed to be agnostic about a code artifact’s runtime environment
I couldn’t accept the risk of running an unsupervised agent on my development machine but I also didn’t want to spin up an expensive, unwieldy VM, so I decided to sandbox the agent in a Docker container, however imperfect that may be2
I needed to combine the code artifacts from multiple research loops in one repo and to manually adapt some of the code as research went on, so the configuration and history of research loops is persisted alongside their code artifact
This last point is worth elaborating on because it’s not obvious why it matters, if your exposure to autoresearch is mainly through breathless tweets from people who allegedly had their codebase successfully rewritten over night. After kicking off a few primitive research loops myself I realised that’s rarely how it plays out. The pitfalls are numerous: the research instructions may not be precise enough; the API of the code artifact may need to evolve as research surfaces new capabilities; optimisation may get stuck in an obvious (to a human) local maximum which the agent can never back out of; it may turn out that the runtime environment is missing a dependency the agent really needs but refuses to install on its own (“too much work”—literal quote from an agent).
For all of these reasons I ended up stopping and restarting research loops often, sometimes reverting experiments, sometimes interleaving manual code changes with the outcome from successful experiments. To support all of that and provide a solid developer experience I came up with the concept of a lab, probably my main contribution here which will hopefully outlive the specifics of the library.
A lab allows any developer—or, for that matter, another agent or some automated pipeline—to start, stop, continue and branch a well-defined autoresearch loop. It consists of a small number of files that can be committed alongside the artifact produced by the research. This includes the research instructions for the agent and the implementation of a backend (in Python), a small interface that computes the metric the lab is optimising for.
The library ships with the “arl” executable that acts as the lab orchestrator. Its “arl run” command starts a Docker container with the agent, waits for the agent to signal that it’s reached the end of an experiment and then uses the backend to compute the metric. It appends the outcome to a results.tsv file which it git commits at the end of each experiment along with the new version of the artifact.
To get started refer to the README. Here’s what a typical sequence of commands looks like (this assumes a Python environment has been created with uv and the autoresearch-lab package is installed in it):
# Initialise a lab in the current directory
uv run arl init --name “my-lab”
# Before continuing edit the generated files: lab.toml, backend.py, AGENT.md
# Start the research loop and run it for 20 experiments
uv run arl run --max-iterations 20
# Show metrics for the state of the artifact after those experiments
uv run arl eval
# List experiments so far & visualise progression in an interactive plot
uv run arl results
uv run arl plot
# Continue research with an extra prompt and pass-through arguments for Claude Code
# (if you can afford it you probably want to use "--effort high" most of the time)
uv run arl run --prompt "prioritise optimising latency" -- --effort highIt isn’t quite as quick to get started with Autoresearch Lab as maybe I’d like. Setting up a lab requires some upfront effort, e.g., you need to implement a backend in Python. But I’ve learned from even just my relatively small-scale applications that this investment pays off.
Just because an architectural pattern is easy to grasp doesn’t at all mean it’s easy to put it into practice. I think autoresearch-at-large has enough hidden complexity that it will spawn a whole new class of software in support of it, especially when, as Karpathy predicts, people start bringing whole swarms of agents to it.
Autoresearching better text recognition for phones
A while ago I wrote about how I like to read books in languages I’m not that fluent in and what my ideal user experience for that looks like. Recently I started reading a major novel in its original language, and it’s one that may come across as so obnoxiously performative that I feel the need to hide the details in a footnote3… The point is that this led me again to experiment with augmenting my reading experience on paper with language study tools on my phone.
Crucially, the seamless integration of a paper book with digital tools needs a way to accurately scan the text on a page with a phone. When I prototyped an app for this I found out that this isn’t as much of a solved problem as I expected it to be, given that Android and iOS ship with builtin text recognition capabilities. On both platforms these yield mediocre results when naively applied to a photo of a book page: the camera angle and page curvature mess with the quality and order of the recognised text; bits of the facing page pollute the text of the actual page you care about; paragraph structure is lost.
This is a great example of a problem suited to autoresearch. I could easily put together a ground truth dataset of book page photos, define a metric that expresses how accurately text is extracted from those photos and then let a research loop discover and optimise the code to do that.
I released what came out of this as BookSnap, a platform-independent (React Native) library which contains within it two labs, one each for the native Android and the native iOS code that does the bulk of the work.4 The metric that the labs optimise for is Character Error Rate (CER), commonly used in the field for this purpose. This plot (generated with Autoresearch Lab’s “arl plot” command) shows how CER got better/lower as more experiments ran:
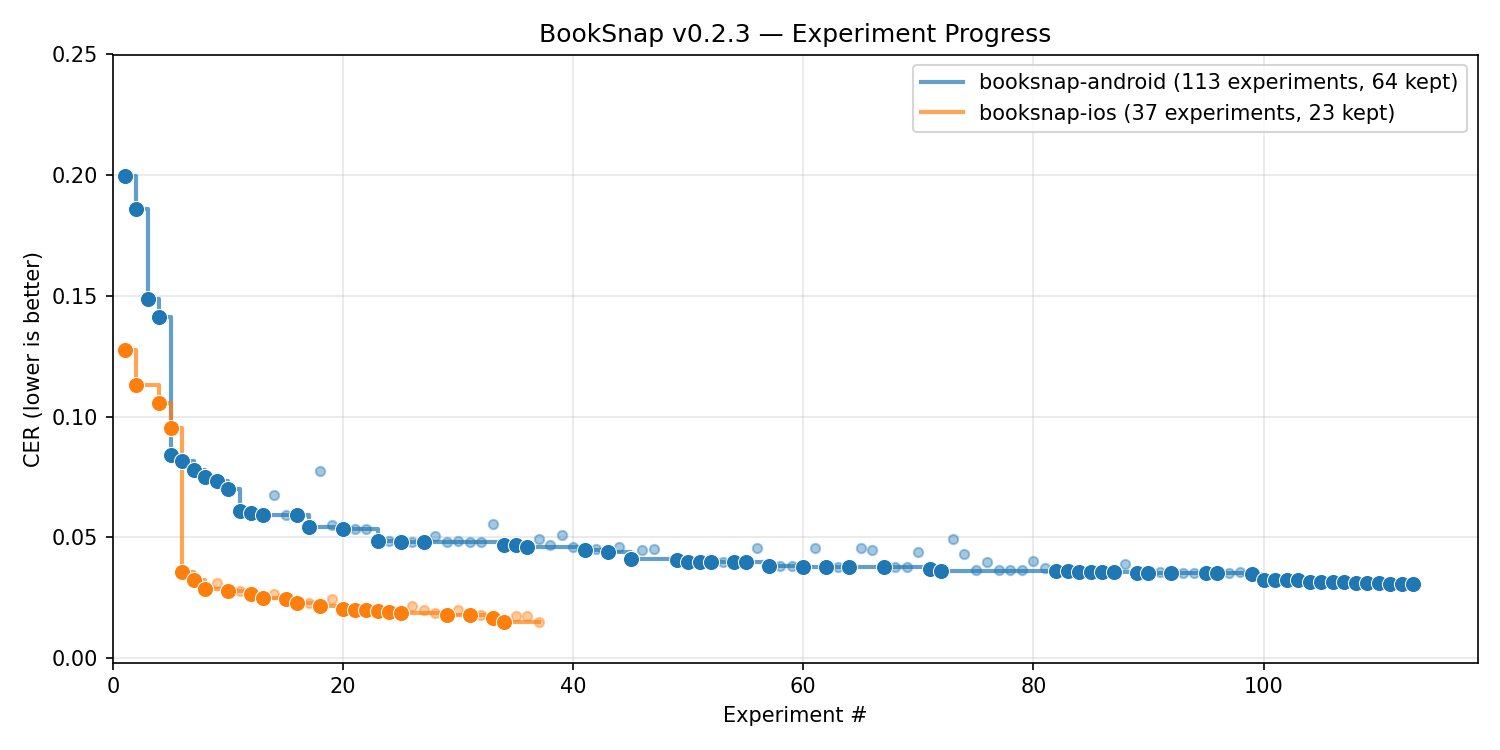
Progress flattened out after a few experiments, though significant improvements may still be discovered if I continued the research loops. I stopped there for now because it’s just as likely that more experiments would overfit the ground truth dataset5. I’m more inclined to continue the research or even restart it from baseline when a next major model drops (i.e., Claude Mythos which, we just learned, is allegedly soooo powerful as to require withholding from the general public to prevent a global cybersecurity meltdown).
This is a huge upside of the autoresearch architecture in general and of the lab approach in particular that I haven’t mentioned yet. With the right setup it’s trivial to take advantage of any future advances in the coding agent ecosystem right away. Autoresearch Lab lets me plug in a new model version or even just new Claude Code flags and have the labs build on the existing code or rewrite it from scratch, with a single command. Since the code was (mostly) generated by autoresearch and I’ve barely looked at it I don’t feel attached to it and have no qualms about scrapping it.
All those developers bragging about never reading the code that their coding agent spits out, is it this feeling of non-attachment that they’re chasing? I get the allure now but I prefer to experience it within the controlled confines of a lab set up for autoresearch.
Intelligent dummies
In trying to understand and improve agent behavior under autoresearch constraints I’ve now watched hours of research loops in action. It’s quite mesmerising! And it’s also exasperating because of the many times an agent will start down a path that I, a reasonably intelligent human, can immediately tell is pointless and will result in a discarded experiment.
I find myself torn between two conflicting perspectives on this. One is through the lens of the famous quote attributed to Thomas Edison: genius is 1% inspiration and 99% perspiration. An agent under autoresearch may simply beat any human at the task because it can perspire all day and night (as long as you keep topping up its token budget). Is an agent that spends 50% of its perspiration on objectively dumb stuff exhibiting something that, in aggregate, we should call genius or intelligence? It seems like a distinct quality to me, and it leads me to agree with Helen Toner that the term “AGI” has run its course.
The other perspective is one that often gets lost in the hype. Yes, frontier coding models are tremendously useful but as of right now they propose dumb solutions all the time. Production software in the long run needs defences against too many of those solutions seeping in, whether it be the judgment of experienced engineers or metric-driven architectures like autoresearch.
I haven’t published anything here in a while, partly because I kinda nerdsniped myself wanting to conquer autoresearch. It took me a while to unwind the stack of insights I was accumulating and package it usefully in the form of the Autoresearch Lab and BookSnap libraries.
Going forward I may not stick to my original goal of publishing something roughly every 2 weeks because a different goal is more important to me: What I write about must be grounded in real code, real applications or at least in a public, usable prototype. I show my work; this isn’t the place where you come for hype, speculation or pure thought leadership. Subscribe above for future dispatches from the edge of product and engineering in the AI era.
—Nik
I previously wrote about my reluctance to jump onto the prairie wagon to Gas Town because it doesn’t seem to address this question at all.
Obligatory disclaimer: Docker isn’t a true security sandbox. It’s still risky to run Autoresearch Lab on a random machine. For stronger isolation you should operate a lab only inside a VM. The agent in the container also has full network access by default, so it’s prone to prompt injection and may exfiltrate the code in your lab; do not include secrets in it.
It’s Proust, in French (À la autorecherche du temps perdu)
In the pre-AI era I would never have attempted to build something in the React Native ecosystem, not having worked in mobile apps for more than 10 years. Claude Code made this a breeze, relatively speaking, though I have to say a React Native library with native code is still one of the most convoluted build environments I’ve ever encountered.
The dataset consists of 34 photos of book pages in 4 languages (English, French, Italian, German). A diff report generated at release shows each sample and its performance against the metric. This may seem like a small number of samples but I took pains to select a diversity of camera angles, lighting conditions, page curvatures and layouts. If you’re looking for tasks that humans are still good for, assembling ground truth data is one of them.